Building a Vector RAG System with GQLPT
This guide explains how to build a Vector RAG (Retrieval-Augmented Generation) system on top of GQLPT to enhance GraphQL query generation using schema embeddings and Neo4j, particularly for large and complex schemas.
Introduction
Large GraphQL schemas pose challenges for AI-based query generation:
- High latency and costs due to large payload sizes
- Potential quality degradation as AI models struggle with extensive information
Vector RAG with GQLPT addresses these issues by:
- Preprocessing and embedding the GraphQL schema
- Storing embeddings in Neo4j
- Retrieving only relevant schema parts for each query
- Generating tailored subset schemas for efficient query generation
This approach reduces AI model load, improves response times, and enhances query quality for large schemas.
Overview
The Vector RAG system for GQLPT has two main components:
- Schema Uploader: Embeds the GraphQL schema and stores it in Neo4j.
- Query Generator: Retrieves relevant schema parts and generates queries using GQLPT.
Prerequisites
- GQLPT installed in your project
- Neo4j database set up and running
- OpenAI API key for embeddings and query generation
How It Works
- Schema Uploading: Parse schema, embed types and fields, store in Neo4j.
- Query Generation: Embed user query, retrieve similar schema nodes, construct partial schema, generate GraphQL query with GQLPT.
Schema Uploader
The schema uploader processes your GraphQL schema, creates embeddings for each type and field, and stores them in Neo4j.
Pseudo-code for Schema Uploading
function uploadSchema():
connect to Neo4j
connect to GQLPT client
clear existing schema nodes in Neo4j
parse GraphQL schema
for each type and field in schema:
create embedding
store in Neo4j with metadata
close Neo4j connection
Neo4j Queries for Schema Upload
// Clear existing schema nodes
MATCH (n:SchemaNode {schemaHash: $schemaHash}) DETACH DELETE n
// Store type node
CREATE (n:SchemaNode:ObjectType)
SET n = $props
SET n.vector = $vector
// Store field node and link to parent type
MATCH (t:SchemaNode {name: $parentType, schemaHash: $schemaHash})
CREATE (f:SchemaNode:Field)
SET f = $props
SET f.vector = $vector
CREATE (t)-[:HAS_FIELD]->(f)
Example: Uploading a Schema
Let's consider the following GraphQL schema:
type Login {
id: ID!
createdAt: String!
user: User!
}
type User {
name: String!
logins: [Login!]!
}
input UserWhere {
name: String!
}
input DateWhere {
gt: String
lt: String
}
input LoginWhere {
date: DateWhere
user: UserWhere
}
type Query {
logins(where: LoginWhere): [Login!]!
users(where: UserWhere): [User!]!
}
When you upload this schema using the Schema Uploader, it will generate a graph structure in Neo4j that looks like this:
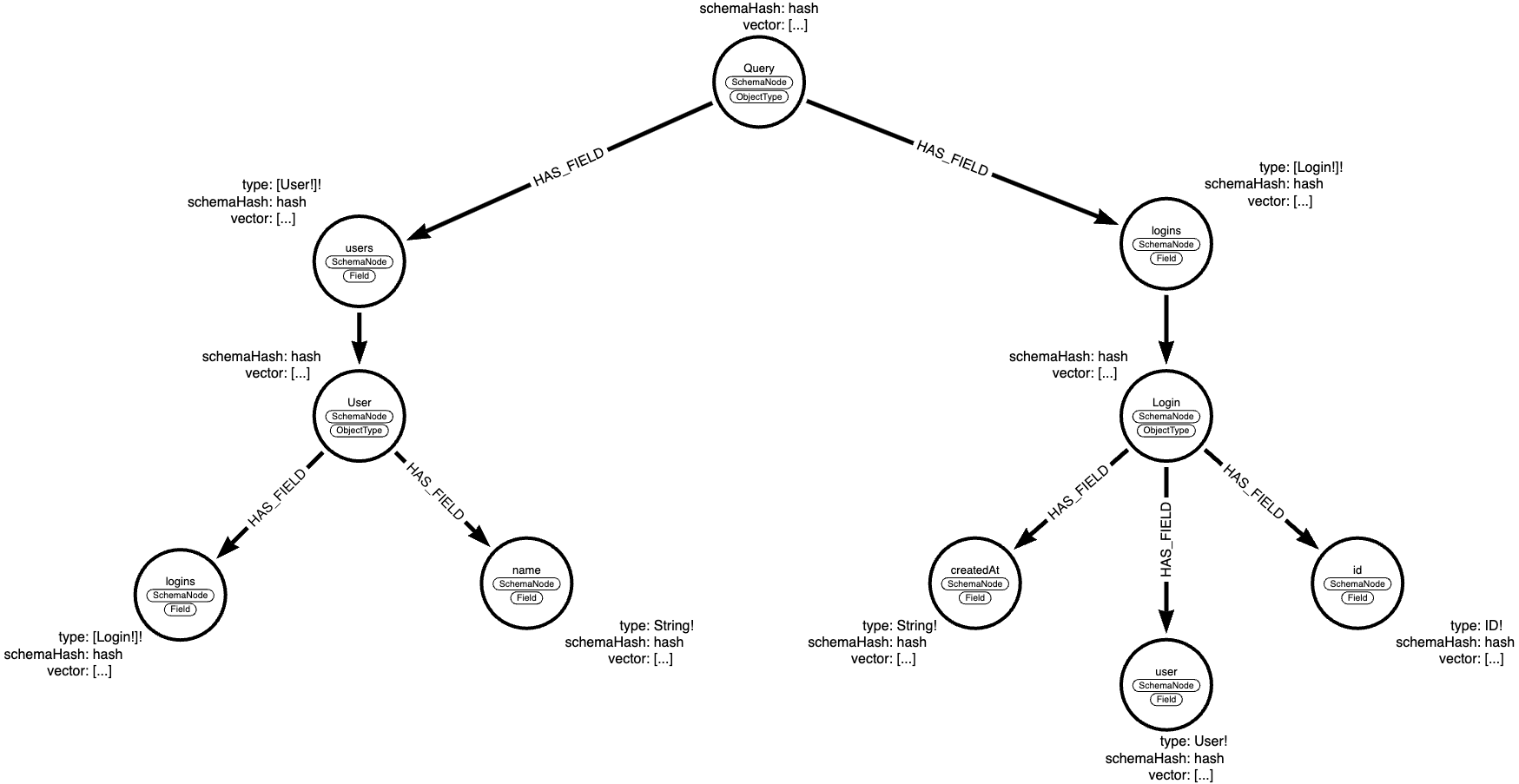
In this graph:
- Each node represents a type or field from the GraphQL schema.
- Nodes are labeled as either
SchemaNode:ObjectTypeorSchemaNode:Field. - Each node has properties including
schemaHashandvector(the embedded representation). HAS_FIELDrelationships connect object types to their fields.- The
typeproperty on field nodes indicates the GraphQL type of that field.
This structure allows for efficient similarity searches when generating queries, as we can quickly traverse the graph to find relevant schema components based on the user's input.
Query Generator
The query generator retrieves relevant schema parts based on the user's query and uses GQLPT to generate the GraphQL query.
Example Plain Text Query
Let's consider the following plain text query:
Find users with name John Doe
This natural language query will be used as input for the query generation process.
Pseudo-code for Query Generation
function generateQuery(plainTextQuery):
connect to Neo4j
connect to GQLPT client
create embedding for plainTextQuery
retrieve relevant schema nodes from Neo4j
create partial GraphQL schema from relevant nodes
use GQLPT to generate query based on partial schema and plainTextQuery
return generated query and variables
Neo4j Query for Retrieving Relevant Nodes
MATCH (n:SchemaNode {schemaHash: $schemaHash})
WITH n, gds.similarity.cosine(n.vector, $queryVector) AS similarity
ORDER BY similarity DESC
LIMIT 20
RETURN n.definition, n.kind, n.name, similarity
In this query, $queryVector would be the embedding of our plain text query "Find users with name John Doe".
Creating a Partial Schema
To create a partial schema from the retrieved nodes:
- Parse the definition of each retrieved node.
- Create GraphQL types for each node using a library like
graphql-js. - Assemble these types into a
GraphQLSchemaobject.
Pseudo-code for creating a partial schema:
function createPartialSchema(relevantNodes):
typeMap = {}
for node in relevantNodes:
if node is ObjectType or InputObjectType:
parse node definition
create GraphQL type
add to typeMap
schemaConfig = {
query: typeMap["Query"],
mutation: typeMap["Mutation"] // if exists
}
return new GraphQLSchema(schemaConfig)
This partial schema, along with the original plain text query "Find users with name John Doe", is then used by GQLPT to generate the final GraphQL query.
Benefits
- Improved query relevance by focusing on the most similar parts of the schema.
- Faster query generation for large schemas by reducing the context size.
- Better handling of complex schemas with many types and fields.
Considerations
- Regularly update the embedded schema when your GraphQL schema changes.
- Fine-tune the similarity threshold and the number of retrieved nodes for optimal performance.
- Monitor and optimize Neo4j queries for large schemas to ensure quick retrieval.
By implementing this Vector RAG system with GQLPT, you can significantly enhance the quality and relevance of generated GraphQL queries, especially for large and complex schemas.